The data were retrieved from the NASA ADS (Astrophysics Data System) which is
a large compilation of different datafiles related to astronomy and
astrophysics. After logging in to the NASA ADS one can get a listing of the
catalogues available in the system. It is also possible to get a description
of the catalogue which describes the catalogue in general and
gives information about the specific format of the data (i.e. which columns
contain what information). We used data from two catalogues: The CfA
Redshift Catalogue and the CfA Redshift Catalogue with V 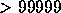 . These
catalogues contain slightly different information about the galaxies,
with the former being far more detailed than the latter.
This, however,
is of no significance, since the only information we needed was the coordinates
of the objects and thier redshifts. In the CfA Redshift Catalogue the redshift
is listed as a velocity and needed a small conversion to redshift.
. These
catalogues contain slightly different information about the galaxies,
with the former being far more detailed than the latter.
This, however,
is of no significance, since the only information we needed was the coordinates
of the objects and thier redshifts. In the CfA Redshift Catalogue the redshift
is listed as a velocity and needed a small conversion to redshift.
The data were read by means of the SQL (Structured Query Language)
composition editor
under the Queries menu in ADS. Here one enters an SQL text specifying
which columns of the data in the catalogue one wants to retrieve and a
path + filename for the output results. We asked for the columns containing
right ascension and declination in decimal degrees, redshift (velocity for
the CfA catalogue with V 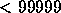 ) and the source for the data specified
by a number refering to a list of survey sources and thus ended up
with a large text file containing coordinates (
) and the source for the data specified
by a number refering to a list of survey sources and thus ended up
with a large text file containing coordinates ( in J2000),
redshift or velocity and source number for a total of 35699
galaxies.
in J2000),
redshift or velocity and source number for a total of 35699
galaxies.
The first step in the preprocessing of the data was the rather tideous work of splitting up the "master-file" into one file for each of the sources. This was accomplished by a lot of manual work and some awk scripts (cf. appendices N and O).
The reason for this splitting of the master-file was to enable us - at a later time - to remove data from specific surveys i.e. pencil-beam surveys. Also the redshift data given as velocity were - by means of awk - recalculated to redshift.
To be able to read in the data in SGI Explorer they had to be converted to
a suitable format. This was done by using an IDL procedure called
ascii_to_bin.pro that first
converted the spherical coordinates (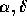 and
and  ) to Cartesian
coordiantes in a straightforward transformation and then produced a binary
file containing the data (extension .dat) and a header file
(extension .idl) readable by the Explorer module IDL2Lat.
The ascii_to_bin.pro procedure is listed in appendix A.
) to Cartesian
coordiantes in a straightforward transformation and then produced a binary
file containing the data (extension .dat) and a header file
(extension .idl) readable by the Explorer module IDL2Lat.
The ascii_to_bin.pro procedure is listed in appendix A.
There were prepared Explorer readable files for the entire set of data
as well as
for relevant subsamples (i.e. without pencil-beams, data with 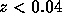 ,
,
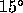 slices in right ascension etc.).
slices in right ascension etc.).